Computer Architecture Simulation
In this section we will learn about general computer architecture simulation techniques, specific different simulation techniques, and where gem5 fits into these frameworks. We will also define some important nomenclature that we will use for the rest of the course.
Recommended reading: Computer Architecture Performance Evaluation Methods by Lieven Eeckhout.
“All models are wrong, some models are useful”
- George Box
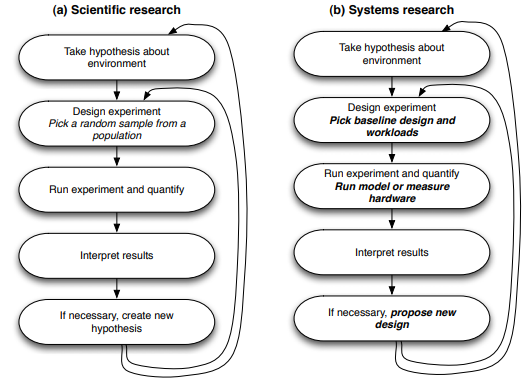
This figure from Computer Architecture Performance Evaluation Methods shows the scientific research method and the similar “systems research” method. In systems research, one key step is to run and measure the model. This step is what gem5 is used for in computer architecture/systems research and will be focus of this course.
For example, a hypothesis may be “If you increase the frequency of the processor then the performance of the workload will improve.” (In this case, let’s assume “improved performance” means a reduction in runtime.)
Now, we need to design an experiment. In our experiment, we will run the workload with a processor at 1 GHz and at 2 GHz and measure the total time to complete the workload in both cases. We can create two gem5 configurations, one with a 1 GHz processor and one with a 2 GHz processor, and keep everything else the same. Then, we can run our workload to see what the performance is.
Why simulation?
- Need a tool to evaluate performance/energy/power etc. of systems that don’t exists
- Very costly to make a chip (can’t make just one)
- Complex system with interdependent parts that are difficult to tease out
- Parameterizable to do design-space exploration
Alternatives to cycle-level simulation?
Analytic models like queueing models and “back of the envelope” models like Amdahl’s Law
Kinds of simulation
- Functional simulation
- RISC-V spike, gem5 “atomic” mode
- Platform to test software
- Validate correctness
- No timing information
- Instrumentation
- PIN, NVBit,
- Often binary translation
- Like trace-based. Not flexible
- Trace-based
- Generate addresses / events and re-execute
- Can be fast (most work done generating the traces, then reused many time)
- If execution depends on timing, isn’t accurate
- “specialized” trace based can look at single aspect (e.g., cache hit/misses)
- Execution-driven
- gem5 and many others
- Function and timing combined
- gem5 is “execute in execute” or “timing directed”
- Full system
- Gem5, many others
- All components modeled with enough fidelity to run “real” application
- Often a mix of functional and full system
Simulation tradeoffs
- Accuracy
- Development time/cost
- Evaluation time/cost
- Coverage
What “level” should we simulate?
- What is the fidelity we want in our simulation?
- Example: New register file design.
- May save a few ps to access… well you should probably do place and route to be sure. Need to do RTL.
- Can save 1 cycle each time even numbered registers are accessed. Can model in gem5 to see effect on the whole program.
- Example: New register file design.
- Often, the answer is a mix of different levels
- gem5 is well suited for this with (well-defined) APIs between components to allow you to swap in/out different fidelity models.
- RTL
- Register-tranfer logic (e.g., verilog)
- Specify every wire and every register
- Very close to the actual ASIC
- Requires (mostly) correct hardware design
- This is “cycle accurate”. Every cycle of the simulator should match the real hardware
- This is very accurate (high fidelity), but it is not very configurable.
- Register-tranfer logic (e.g., verilog)
- C++/Event driven
- Can model things at the cycle “level”, but doesn’t (and usually isn’t) accurate on a cycle-by-cycle level like RTL.
- Can be accurate
- Is parameterizeable
- Define this clearly in terms of how gem5 uses it.
Accelerating simulation
- Parallelism
- Lots of people ask “why is gem5 not parallel?”
- (Personal opinion coming) because it’s an inherently (mostly) serial program.
- Can get parallelism by running different simulations at the same time (throughput, not latency improvement)
- Can get parallelism if modeling multiple different systems (less communication than between cores). See SST section.
- Lots of people ask “why is gem5 not parallel?”
- Use FPGAs
- FireSim is a good example of this.
- Useful for RTL
- Can be cycle-accurate
- Requires RTL (usually), but is almost always less flexible than C++ models.
Important terms
- Full system
- Execute in execute
- Functional vs execution/timing based
- Host vs guest