gem5 Models: CPUs
This is a summary document for the gem5 bootcamp session on CPU models. This tutorial covers following topics:
- gem5 CPU models
- Using gem5 CPU models
- Understanding the CPU model differences via an experiment
Note: This document is meant to complement the slides used in the bootcamp and will refer to the slides for detailed instructions on how to run the experiments of this tutorial.
gem5 CPU Models
Following picture provides an overview of the differences among gem5 CPU models:
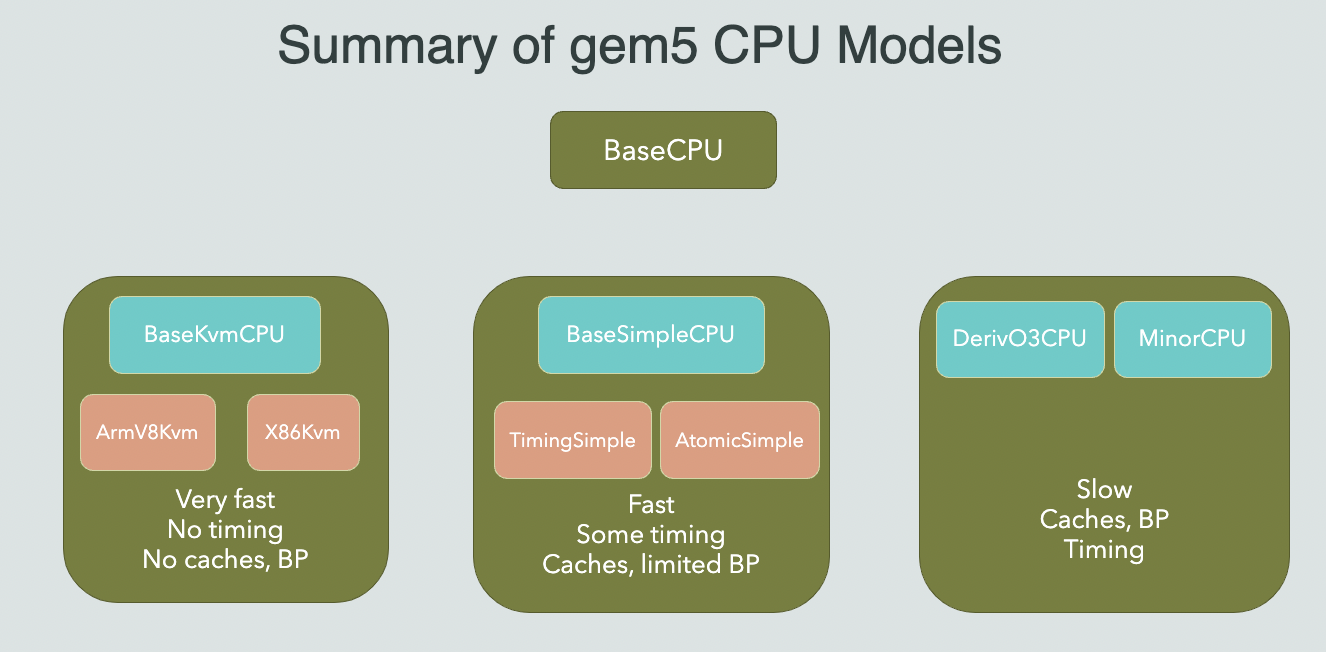 An overview of the differences among gem5 CPU models.
An overview of the differences among gem5 CPU models.
Memory Access Types in gem5:
-
Atomic: Useful for warming up micro-architectural structures, or fast-forwarding. An access completes within a sequence of nested calls.
-
Timing: An access is modeled using split transactions. This type of memory access models queuing delays and resource contention. An access request and response happens via separate functions.
-
Functional: Kind of a backdoor access to memory. Useful for debugging or whenever access to memory is needed without any impact on the simulated system (e.g., loading binaries into memory for SE mode).
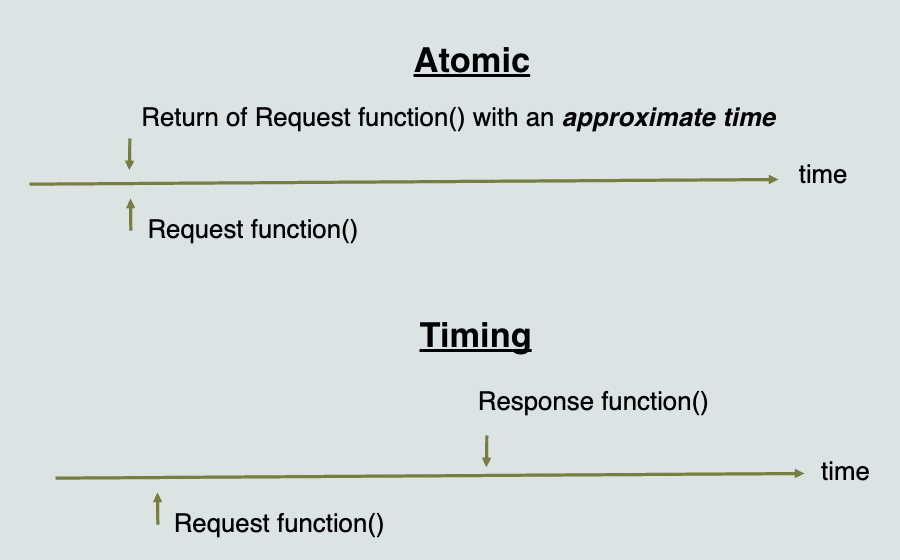 Difference between the Atomic and Timing memory access mode in gem5.
Difference between the Atomic and Timing memory access mode in gem5.
AtomicSimpleCPU
A single instruction per cycle CPU model, which uses Atomic memory accesses.
TimingSimpleCPU
This CPU model executes a single instruction per cycle except memory instructions which are modeled using Timing memory access mode and can take more than one cycle.
O3CPU
This is the most detailed CPU model in gem5 and models an out of order pipeline (mainly based on Alpha 21264 machine). It uses Timing memory access mode and provides the ability to model different delay between pipeline stages and any width for those stages. It also provides parameters to configure many other aspects of an the CPU model e.g., number of physical registers, reservation station and reorder buffer sizes, etc.
MinorCPU
This is gem5’s detailed in-order CPU model. By default this CPU models a four stage pipeline (Fetch1, Fetch2, Decode, Execute), however, the delay between the pipeline stages is configurable. One noteworthy point is that the real instruction decoding happens at Fetch2 stage of MinorCPU and Decode stage is there mostly for bookkeeping.
KvmCPU
This CPU model is used for native execution on x86 and ARM platforms and can be used for fast-forwarding or functional testing. This CPU model uses the KVM (kernel virtual machine) support on the host to run the simulated guest on directly on the host. It requires the guest and host ISA to be the same.
Using the CPU Models
This exercise is meant to cover the use of some of the gem5 CPU models to understand their differences.
The location of the material (scripts/code) used for this exercise can be found in this README. You can follow the instructions from the tutorial slides (slide 20-25) to run the experiments to collect data which will be used to understand the differences among gem5 CPU models.
The instructions (referred above) use a benchmark (a modified version of IntMM from llvm test suite) as a test to run with three gem5 CPU models (Atomic, Timing, and O3) with two different cache sizes (a normal cache size of 32KB and a much smaller cache of 1KB).
Understanding the differences among gem5 CPU models
You can follow the instructions in slides (slide 28-36) to go through this part of the exercise which involves looking at the statistics generated from the gem5 runs from previous section. The main statistics we looked at include the number of simulated operations, and the number of simulated execution cycles.
One of the things that we can observe while comparing the execution cycles across different CPU models is that there is not any significant difference in the number of cycles taken by an Atomic CPU between two different cache sizes. On the other hand, TimingSimple CPU shows a recognizable difference in cycles between two cache sizes. The reason for this difference is that the AtomicSimple CPU does not model the details of the memory system, and the increase in the number of cache misses (with smaller cache size) has no impact on the timing of the memory system. On the other hand, since TimingSimple CPU models the memory details of the memory system, the increase in the number of cache misses (when smaller cache is used) eventually impacts the time spent in the memory system.